8. SQL응용
관계대수 : 데이터베이스 이론에서 대수적 구조를 사용해서 데이터를 모델링하고, 의미론으로 쿼리를 정의하는 이론...
Edgar F.codd가 소개함
데이터 형태의 연산을 정의한 의미론적인 수학기호가 필요했다...
릴레이션 : 가로 행, 세로 열 형태로 되어있는 데이터 묶음 ex)학생
튜플 : 가로 행, 특정 조건에 맞는 전체 속성을 묶는 쌍
속성 : 세로 열
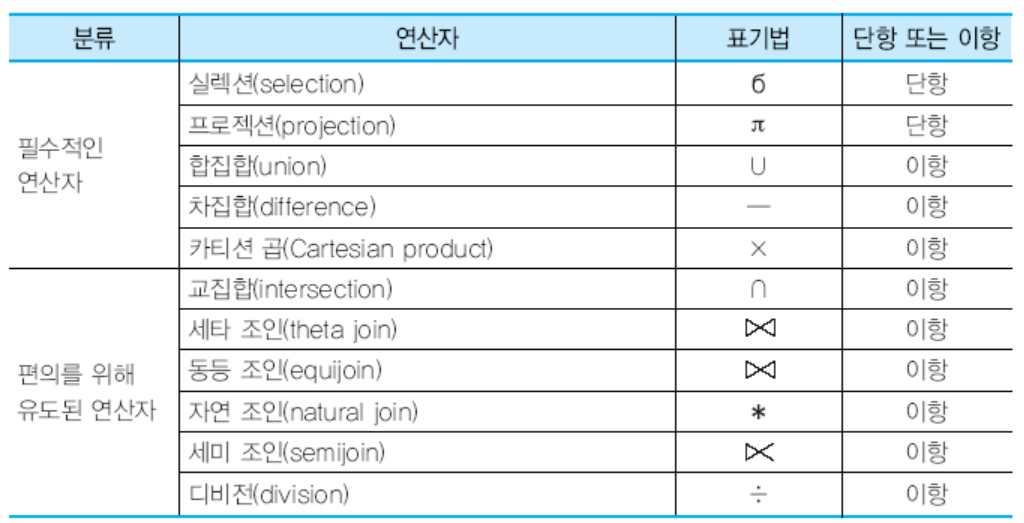
필수연산자 다섯가지 (단항 표시 제외 모두 이항)
- 셀렉션(selection, σ) : 가로행만 가져옴 (단항)
- 프로젝션(projection, π) : 세로 열만 가져옴(단항)
- 합집합 (union,∪)
- 차집합 (difference, –)
- 카티션 곱 혹은 카티션 프로덕트 (Cartesian product, ×)

나머지 조인에 대한 정의
- 세타조인: 조인에 참여하는 두 릴레이션의 속성 값을 비교하고, 조건을 만족하는 튜플만 반환합니다. 세타조인은 =, ≠, ≤, ≥, <, >중에 하나의 조건을 가집니다.
- 동등조인: 세타조인에서 = (는) 연산자를 사용한 조인을 말합니다. 보통 "조인연산"이라고 말하면 사람들은 동등조인으로 알아듣습니다.
- 자연조인: 동등 조인에서 조인에 참여한 속성이 두 번 나오지 않도록, 두 번째 속성을 제거한 결과를 반환합니다. 즉, 중복된 속성을 제거합니다.
- 세미조인: 자연조인을 한 후에, 두 릴레이션 중에 한쪽 릴레이션의 결과만 반환합니다. 이 경우는 왼쪽과 오른쪽 중에 제거할 속성 쪽을 열어두는 형식으로 작성합니다.

표현 형식에서 닫힌 쪽의 릴레이션의 튜플을 반환한다고 외우기
예시

SQL의 종류
- DDL (Data Definition Language): 데이터베이스 객체(테이블, 인덱스, 뷰 등)의 구조를 정의하고 관리하는 데 사용됩니다.
- CREATE: 새로운 데이터베이스 객체를 생성합니다.
- ALTER: 기존 데이터베이스 객체의 구조를 변경합니다.
- DROP: 데이터베이스 객체를 삭제합니다.
- DML (Data Manipulation Language): 데이터베이스 내의 데이터를 조작하는 데 사용됩니다.
- SELECT: 데이터베이스에서 데이터를 조회합니다.
- INSERT: 데이터베이스에 데이터를 삽입합니다.
- UPDATE: 데이터베이스의 데이터를 수정합니다.
- DELETE: 데이터베이스에서 데이터를 삭제합니다.
- DCL (Data Control Language): 데이터베이스에 대한 권한을 제어하는 데 사용됩니다.
- GRANT: 사용자에게 권한을 부여합니다.
- REVOKE: 사용자에게서 권한을 회수합니다.
- TCL (Transaction Control Language): 데이터베이스 내의 트랜잭션을 제어하는 데 사용됩니다.
- COMMIT: 트랜잭션에서 수행된 변경사항을 확정합니다.
- ROLLBACK: 트랜잭션에서 수행된 변경사항을 취소합니다.
- SAVEPOINT: 트랜잭션 내에 저장점을 설정합니다.
용어 정리)
- 데이터베이스 객체: 데이터베이스 객체(Database Object)는 데이터베이스 내에서 생성되고 관리되는 구조나 개체를 의미합니다. (테이블, 뷰, 인덱스 등)
- 테이블(Table): 데이터를 행(Row)과 열(Column) 형태로 저장하는 기본 단위입니다.
- 뷰(View): 하나 이상의 테이블로부터 데이터를 조회하기 위한 가상의 테이블입니다.
- 인덱스(Index): 데이터베이스의 검색 성능을 향상시키기 위해 사용하는 데이터 구조입니다.
- 함수(Function): 특정 작업을 수행하고 값을 반환하는 객체입니다.
- 패키지(Package): 관련된 프로시저와 함수를 하나의 단위로 묶은 객체입니다.
- 트랜잭션(Transaction): 데이터베이스에서 하나의 논리적 작업 단위를 구성하는 일련의 작업(쿼리)입니다. 트랜잭션은 모두 성공하거나 모두 실패해야 하는 원자성을 가지고 있으며, 데이터베이스의 일관성을 유지하기 위해 사용됩니다. 트랜잭션의 주요 특징은 ACID 특성으로 설명할 수 있습니다.
- ACID
- Atomicity 원자성 : 트랜잭션의 연산은 데이터 베이스에 모두 반영되거나 전혀 반영되지 않아야 한다.
- Consistency 일관성 : 트랜잭션이 그 실행을 성공적으로 완료하면, 언제나 일관성 있는 데이터 베이스 상태로 변환
- Isolation 독립성 : 둘 이상의 트랜잭션이 동시에 병행되어 실행되는 경우 어느 하나의 트랜잭션 실행 중에는 다른 트랜잭션의 연산이 끼어들 수 없다.
- Durability 영속성, 지속성 : 성공적으로 완료된 트랜잭션의 경우 시스템이 고장 나더라도 영구적으로 반영되야한다.
DDL예제
DDL(Data Definition Language)
데이터베이스에 데이터를 넣으려면, 테이블(Table)이라는 엑셀시트와 비슷한 것을 만들어야 합니다. 테이블을 만드는 것은 CREATE 라는 키워드로 작성합니다.
가방이라는 테이블을 만들어봅시다.
기본 문법:
CREATE TABLE [테이블명] (
[컬럼명] [데이터타입] [제약조건],
[컬럼명] [데이터타입] [제약조건],
...
);실제 사용 예제
CREATE TABLE Bags (
BagID INT PRIMARY KEY,
Brand VARCHAR(50) NOT NULL,
Model VARCHAR(50) NOT NULL,
Color VARCHAR(30),
Price INT,
Stock INT
);이렇게 하면 Bags라는 테이블을 만드는데 컬럼을 6개를 생성합니다.
각 컬럼은 BagID, Brand, Model, Color, Price, Stock(재고라는 뜻)이며 각 컬럼은 INT(숫자), VARCHAR(50), (30): 50과 30 크기만큼의 문자열 데이터를 할당하도록 되어있습니다.
BagID에 적혀있는 PRIMARY KEY는 제약조건이라고 부르는 옵션 중에 하나입니다. PRIMARY KEY는 "주 키 혹은 PK"라고 부르며 고유하게 각 열을 구별할 수 있도록 중복되지 않은 값이어야 합니다. (사람으로 치면 주민등록번호, 학생의 경우 학번과 같은 것)
NOT NULL 제약 조건은 데이터 값으로 NULL이 들어갈 수 없다는 뜻입니다.
테이블을 수정할 때는 ALTER를 사용합니다.
컬럼 추가
ALTER TABLE [테이블명]
ADD COLUMN [컬럼명] [데이터타입];컬럼 수정
ALTER TABLE [테이블명]
ALTER COLUMN [컬럼명] [새로운 데이터타입 또는 제약조건];컬럼 삭제
ALTER TABLE [테이블명]
DROP COLUMN [컬럼명];Bags라는 테이블에 가방의 재료를 뜻하는 Material이라는 컬럼을 추가해봅시다.
ALTER TABLE Bags
ADD COLUMN Material VARCHAR(50);기존 컬럼의 색상을 30글자에서 50글자를 저장할 수 있게 바꿔봅시다.
ALTER TABLE Bags
ALTER COLUMN Color VARCHAR(50) NOT NULL;stock 컬럼을 삭제해봅시다.
ALTER TABLE Bags
DROP COLUMN Stock;테이블을 삭제하는 방법은 DROP을 사용합니다.
DROP TABLE [테이블명];예제
DROP TABLE Bags;DDL 예제
DDL의 영역
최초로, 아래와 같은 students라는 테이블을 만들고, INSERT를 통해서 삽입하겠습니다.
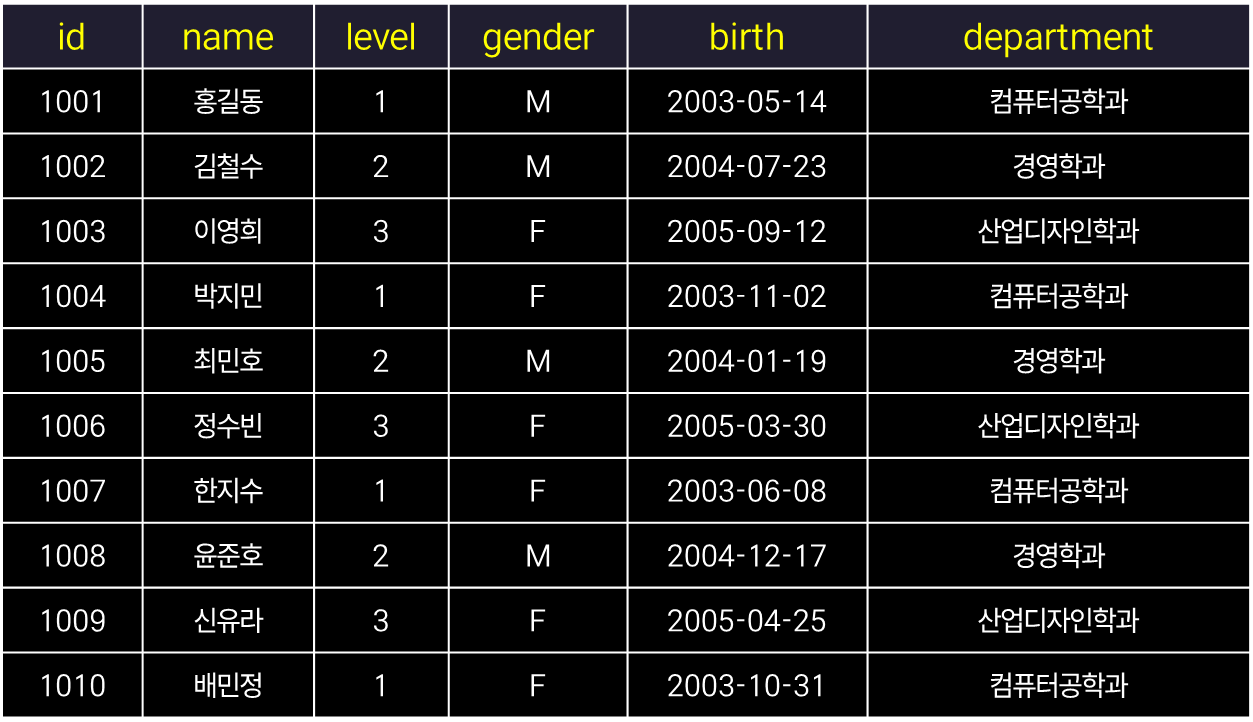
DDL - CREATE를 통한 데이터베이스 테이블 생성
-- 테이블 생성
CREATE TABLE students (
id INT PRIMARY KEY,
name VARCHAR(50),
level INT,
gender CHAR(1),
birth DATE,
department VARCHAR(50)
);이렇게 테이블을 먼저 정의합니다. 이건 앞에서 배웠죠?
보통 학년은 grade로 표기하긴 하지만, gender와 맨 앞 알파벳을 다르게 하려고 level로 설정했습니다.
DML의 영역
DML - INSERT: 데이터 삽입하기
-- 데이터 삽입
INSERT INTO students
(id, name, level, gender, birth, department) VALUES
(1001, '홍길동', 1, 'M', '2003-05-14', '컴퓨터공학과'),
(1002, '김철수', 2, 'M', '2004-07-23', '경영학과'),
(1003, '이영희', 3, 'F', '2005-09-12', '산업디자인학과'),
(1004, '박지민', 1, 'F', '2003-11-02', '컴퓨터공학과'),
(1005, '최민호', 2, 'M', '2004-01-19', '경영학과'),
(1006, '정수빈', 3, 'F', '2005-03-30', '산업디자인학과'),
(1007, '한지수', 1, 'F', '2003-06-08', '컴퓨터공학과'),
(1008, '윤준호', 2, 'M', '2004-12-17', '경영학과'),
(1009, '신유라', 3, 'F', '2005-04-25', '산업디자인학과'),
(1010, '배민정', 1, 'F', '2003-10-31', '컴퓨터공학과');이렇게 데이터를 삽입합니다.
사실 데이터를 삽입한 것만으로는 데이터베이스는 표를 보여주지 않습니다.
데이터베이스에서는 SELECT를 해야 VIEW라는 형태로 보여주는데,
우리는 시험 공부하고 있으니까 그냥 보여준다고 가정하겠습니다
(SELECT * from students)

DML - UPDATE: 데이터 변경하기
이제 update로 값을 바꿔보겠습니다.
UPDATE의 문법은 아래와 같습니다.
UPDATE 테이블 SET 열 = 변경할 값 where 조건
- id가 1001인 학생의 ‘level’(학년)을 2로 업데이트 한다.
UPDATE students
SET level = 2
WHERE id = 1001;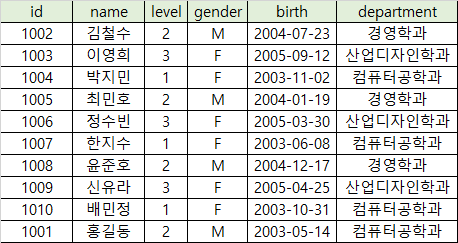
이렇게 하면 id가 1001인 홍길동의 학년이 바뀌어 있습니다.
튜플들이 보여지는 순서에 크게 신경쓰지 마세요.
DB마다 보여주는게 다를 수도 있고, 명백하게는 나중에 select하면서 오름차순, 내림차순을 따로 지시할 수 있습니다.
- name이 '김철수'인 학생의 department를 '컴퓨터공학과'로 업데이트합니다.
UPDATE students
SET department = '컴퓨터공학과'
WHERE name = '김철수';
김철수가 컴퓨터공학과로 변경되었습니다.
DML - DELETE: 데이터 삭제하기
기본형태: DELETE FROM 테이블 WHERE 조건
- id가 1004인 학생의 데이터를 삭제합니다.
DELETE FROM students
WHERE id = 1004;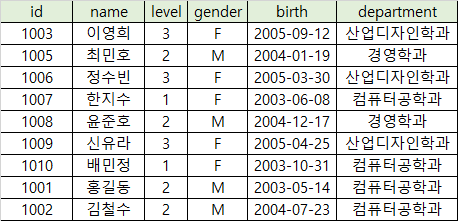
id가 1004였던 학생 데이터가 삭제되었습니다.
- department가 '산업디자인학과'인 모든 학생 데이터를 삭제합니다.
DELETE FROM students
WHERE department = '산업디자인학과';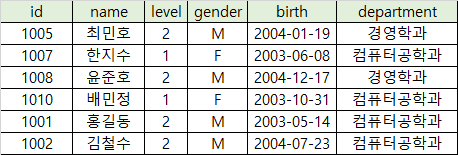
학과가 산업디자인학과인 학생 데이터가 모두 삭제되었습니다.
위에서 데이터를 너무 많이 삭제했습니다.
테이블을 DROP -> CREATE -> INSERT를 해서 원복했다고 가정하고 SELECT를 진행하겠습니다.
DML - SELECT: 데이터 조회하기
SELECT의 기본 문법:
SELECT 열1, 열2,.. FROM 테이블명
WHERE 조건
GROUP BY 묶을 그룹명
HAVING 기타 조건
ORDER BY 정렬 순서 조건
여기서 WHERE 이후로는 목적에 따라 생략해도 됩니다. 상황에 따라 조회하는 조건을 달라질 수 있으니까요.
- 전체 행을 조회하는 방법
테이블의 전체 행을 조회할 때는 보통 *을 많이 씁니다.
*은 SQL에서 ALL을 뜻합니다. 모든 것을 다 가져오라는 것이죠.
SELECT * FROM students;students 테이블이 가지고 있는 모든 데이터 튜플을 다 가져오라는 명령입니다.
<조회결과>

여기서 DISTINCT라는 키워드를 쓰면 고유하게 속성만 뽑아서 조회할 수 있습니다.
- 중복하지 않고, 고유하게 birth만 가져와라
SELECT DISTINCT birth
FROM students;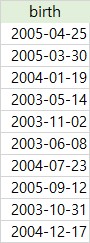
- 중복하지 않고, 고유하게 학과만 가져와라
SELECT DISTINCT department
FROM students;
SELECT + GROUP BY
GROUP BY는 말 그대로 그룹을 묶는 것입니다. 여러 행을 하나의 특성으로 묶는다고 하면, 강제로 묶을 수는 없겠죠? 뭔가를 연산하거나 묶어서 표현할만한 다른 수식과 함께 사용해야합니다.
- COUNT를 사용한 예제
각 학과별 학생 수를 계산합니다.
SELECT department, COUNT(*)
FROM students
GROUP BY department;
- SUM을 사용한 예제
학과별로 학생들의 학년 합계를 계산합니다.
SELECT department, SUM(level)
FROM students
GROUP BY department;
- MIN을 사용한 예제
학과별로 가장 낮은 학년을 찾습니다.
SELECT department, MIN(birth) AS youngest_date_of_birth
FROM students
GROUP BY department;이 경우에는 MIN(birth)를 AS라는 단어로 컬럼명을 설정한 것입니다.

- MAX를 사용한 예제
학과별로 가장 높은 학년을 찾습니다.
SELECT department, MAX(birth) AS oldest
FROM students
GROUP BY department;
이번 예제도 컬럼명을 AS를 통해 지정한 대로 출력됐습니다.
- AVG를 사용한 예제
평균 학년을 계산합니다.
-- 각 학과에서 평균 학년을 소수점 두 자리까지 표기하는 예제
SELECT department, ROUND(AVG(level), 2) AS avg_level
FROM students
GROUP BY department;일반적인 표기법인
SELECT department, AVG(level)
FROM students
GROUP BY department;
이렇게 표기하는 경우 소수점이 끝까지 나올 수 있습니다. 그래서 ROUND라는 함수로 소수점 아래 둘째자리까지만 출력합니다.

- WHERE를 통한 추가 조건을 주는 방법
학년이 2 이상인 학생들만 대상으로 학과별 학생 수를 계산합니다.
SELECT department, COUNT(*)
FROM students
WHERE level >= 2
GROUP BY department;
7. WHERE와 HAVING을 사용한 예제
학년이 2 이상인 학생들만 대상으로 학과별 학생 수를 계산하고, 학생 수가 2명 이상인 학과를 찾습니다.
SELECT department, COUNT(*)
FROM students
WHERE level >= 2
GROUP BY department
HAVING COUNT(*) >= 2;HAVING의 경우에는 GROUP BY로 그룹화 된 결과에 대해서 조건을 적용할 때 사용합니다.
해석하면 이렇게 할 수 있습니다.
- WHERE 조건: level >= 2인 레코드만 선택합니다. 즉, 학년이 2 이상인 학생들만 필터링됩니다.
- GROUP BY: department 컬럼을 기준으로 그룹화합니다. 학과별로 그룹이 만들어집니다.
- COUNT(*): 각 그룹(학과) 내의 학생 수를 셉니다.
- HAVING 조건: 각 그룹의 학생 수가 2명 이상인 경우만 선택합니다. 학과별로 학년이 2 이상인 학생이 2명 이상 있는 경우만 결과에 포함됩니다.

조인과 SQL 기출문제
아래 2개의 테이블이 있을 때, 쿼리 결과를 테이블로 작성하여라.
<학생 테이블>

<성적 테이블>

(문제)
SELECT 과목이름
FROM 성적
WHERE EXISTS (SELECT 학번
FROM 학생 WHERE 학생.학번 = 성적.학번 AND 학생.학과 IN ('전산', '전기') AND 학생.주소 = '경기');(해설)
쿼리를 볼 때는 가장 중요한 것은 select 바로 앞을 보는 것입니다. 그것이 최종 속성명이 될 것이니까요.
지금 문제는 과목이름을 가져오고 싶어합니다. 그 뒤는 성적 테이블입니다.
학생 테이블에서 (학생테이블에서의 학번과 성적테이블에서 학번이 같은 것을 가져오되) 그 중에서도 학생 테이블에서 학과가 "전산" 또는 "전기"에 들어가면서도 주소가 "경기"인 학생들에 대해서 성적 테이블에서 일치하는 과목 이름을 반환하라는 뜻입니다.
지금 저 조건을 만족하는 것은 학번이 2000, 4000인 학생입니다.
성적 테이블에서 이와 매칭되면서 가져올 수 있는 과목이름은 DB,DB, 운영체제입니다.
(정답)

DCL 예제
GRANT
GRANT 명령어는 사용자가 데이터베이스 객체(테이블, 뷰, 프로시저 등)에 대해 특정 작업을 수행할 수 있는 권한을 부여합니다.
예제 1: 테이블에 대한 SELECT 권한 부여
GRANT SELECT ON employees TO user1;
user1 사용자에게 employees 테이블에 대한 SELECT 권한을 부여합니다.
예제 2: 테이블에 대한 INSERT 권한 부여
GRANT INSERT ON sales TO user2;
예제 3: 테이블에 대한 여러 권한 부여
GRANT SELECT, UPDATE, DELETE ON orders TO user3;
user3 사용자에게 orders 테이블에 대한 SELECT, UPDATE, DELETE 권한을 부여합니다.
예제 4: Weekend 유저의 192.168.1.100 주소로 모든 권한을 부여합니다.
GRANT ALL ON Users TO 'Weekend'@'192.168.1.100';REVOKE
REVOKE 명령어는 사용자가 데이터베이스 객체에 대해 가지고 있는 권한을 회수합니다.
예제 1: 테이블에 대한 SELECT 권한 회수
REVOKE SELECT ON employees FROM user1;
user1 사용자에게 부여했던 employees 테이블에 대한 SELECT 권한을 회수합니다.
예제 2: 테이블에 대한 INSERT 권한 회수
REVOKE INSERT ON sales FROM user2;user2 사용자에게 부여했던 sales 테이블에 대한 INSERT 권한을 회수합니다.
예제 3: 테이블에 대한 여러 권한 회수
REVOKE SELECT, UPDATE, DELETE ON orders FROM user3;user3 사용자에게 부여했던 orders 테이블에 대한 SELECT, UPDATE, DELETE 권한을 회수합니다.
예제 4: Weekend 유저의 192.168.1.100 주소로 있는 모든 권한을 회수합니다.
REVOKE ALL ON Users FROM 'Weekend'@'192.168.1.100';'자격증' 카테고리의 다른 글
| AWS SAA-C03 Dump 1-50 (1) | 2026.01.28 |
|---|---|
| 리눅스마스터 - 사용자 관리 (0) | 2025.04.13 |
| 정렬 알고리즘 (0) | 2024.10.17 |
| 소프트웨어 보안 구축 (9) | 2024.10.16 |
| 서버 프로그램 구현/ 인터페이스 구현/ 화면설계 / 애플리케이션 테스트 관리 (2) | 2024.10.15 |

